
データの様々な抽出方法
まずはコマンドプロンプトで以下を順に実行し、データを拡張しておきます。
delete from student;
alter table student add age int;
insert into student (number,name,create_datetime,update_datetime,age) values (1,”鈴木一郎”,NOW(),NOW(),18);
insert into student (number,name,create_datetime,update_datetime,age) values (2,”鈴木二郎”,NOW(),NOW(),32);
insert into student (number,name,create_datetime,update_datetime,age) values (3,”鈴木三郎”,NOW(),NOW(),22);
insert into student (number,name,create_datetime,update_datetime,age) values (4,”鈴木四郎”,NOW(),NOW(),51);
insert into student (number,name,create_datetime,update_datetime,age) values (5,”鈴木五郎”,NOW(),NOW(),47);
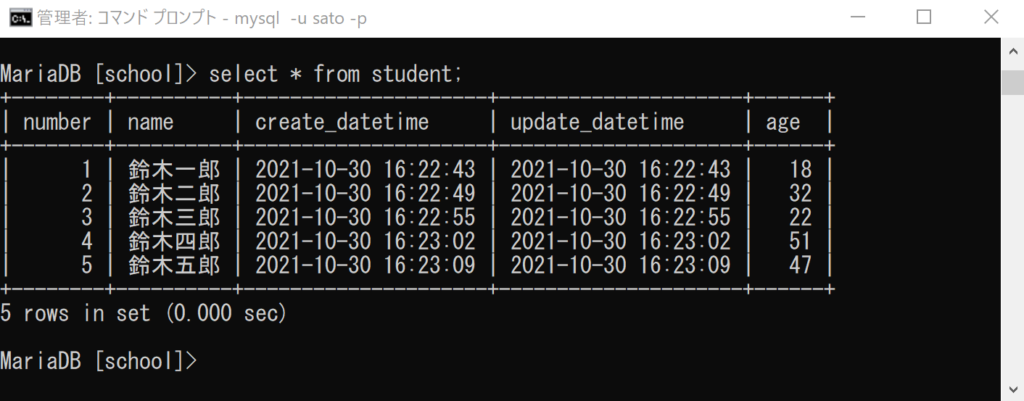
実行後にレコードを取得すると、以下のようになっています。
COUNT
データの件数を取得する命令です。
コマンドプロンプトで以下のSQLを実行します。
select count(*) from student;
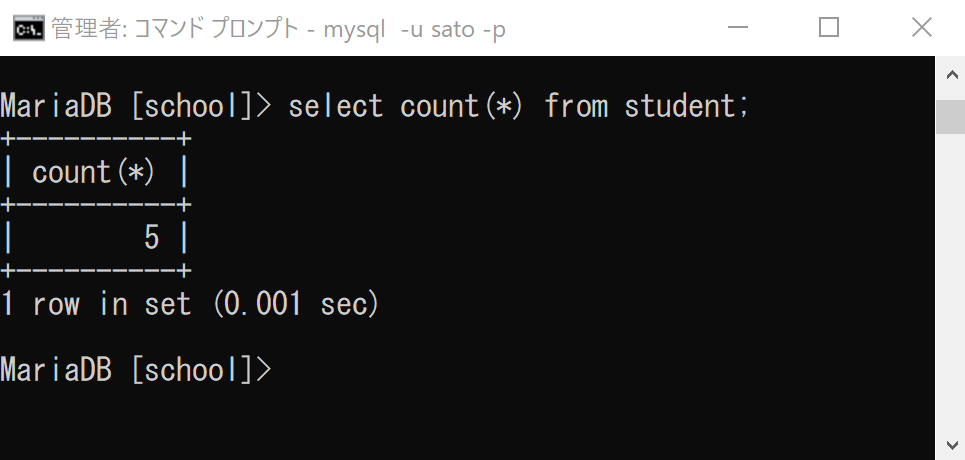
「count(*)」の「(*)」はすべてのデータ(レコード)という意味で、「count(*)」は「すべてのレコードの数」という意味になります。
ここでは、studentテーブルにはデータ(レコード)は5つあるので、「5」と表示されています。
MAX、MIN
レコードが増えていくと、その中の最大値・最小値のデータを取得したい場合があります。その場合にMAX、MINを使います。
コマンドプロンプトで以下のSQLを実行します。
select max(age) from student;
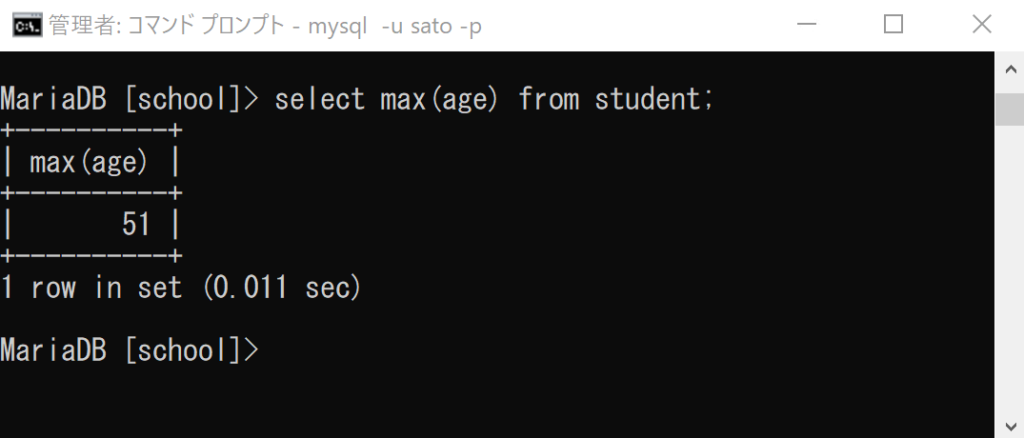
「max(age)」は「ageというカラムの値の内、最大値を取得する」という意味です。
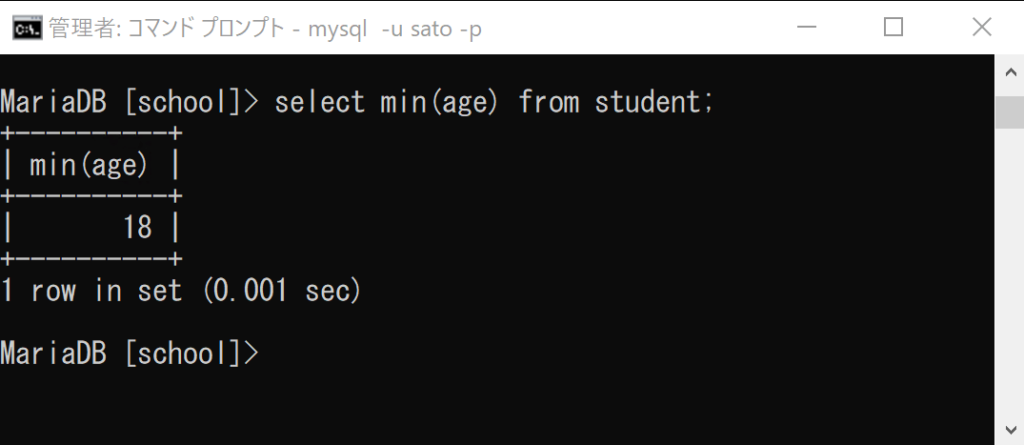
ここでは「51」が取得できました。
次に最小値を取得します。
select min(age) from student;
ORDER BY
データの順番を並び替えるには、ORDER BYを使用します。
コマンドプロンプトで以下のSQLを実行します。
select * from student order by age;
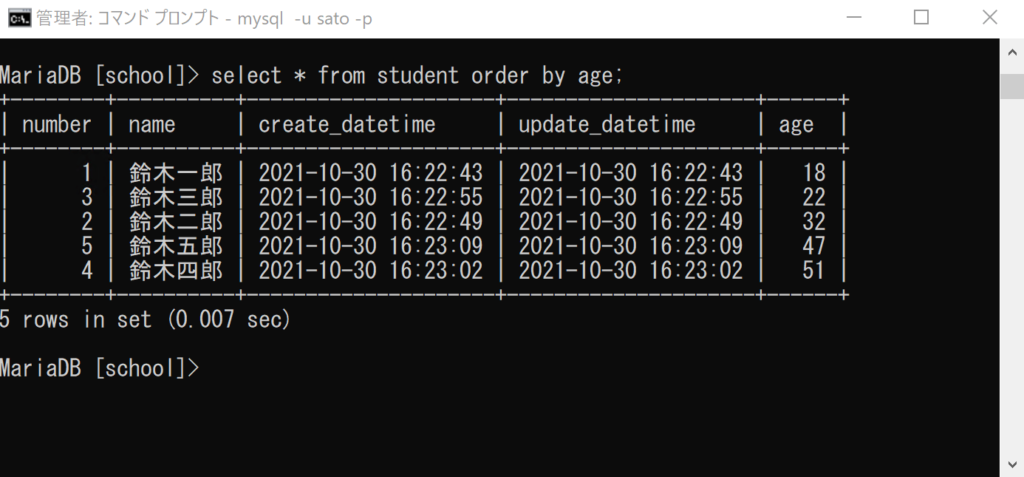
「order by age」は「ageカラムの値を(昇順に)並び替える」という意味になります。ageのデータが「18」「22」「32」「47」「51」のように昇順になっていますね。
降順にするには、以下のように実行します。
select * from student order by age desc;
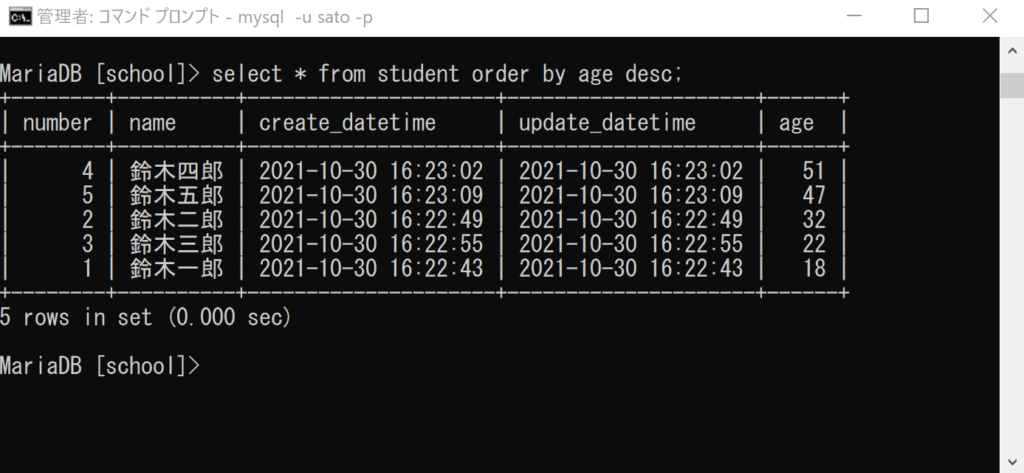
降順にするには「desc」を付けます。ageのデータが「51」「47」「32」「22」「18」のように降順になっていますね。
AND
「~かつ…」のようにAND条件でデータを抽出することができます。
コマンドプロンプトで以下のSQLを実行します。
select * from student where number >= 2 and age < 40;
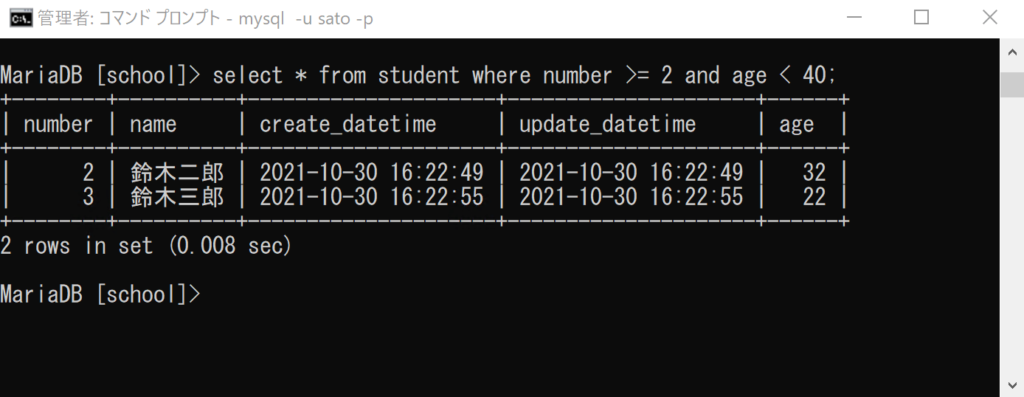
「where」は「~の場合に(レコードを抽出する)」という意味でした。
ここでは「numberカラムの値が2以上」かつ「ageカラムの値が40未満」のレコードを抽出する、という意味になります。
OR
「~または…」のようにOR条件でデータを抽出することができます。
コマンドプロンプトで以下のSQLを実行します。
select * from student where number = 2 or age < 40;
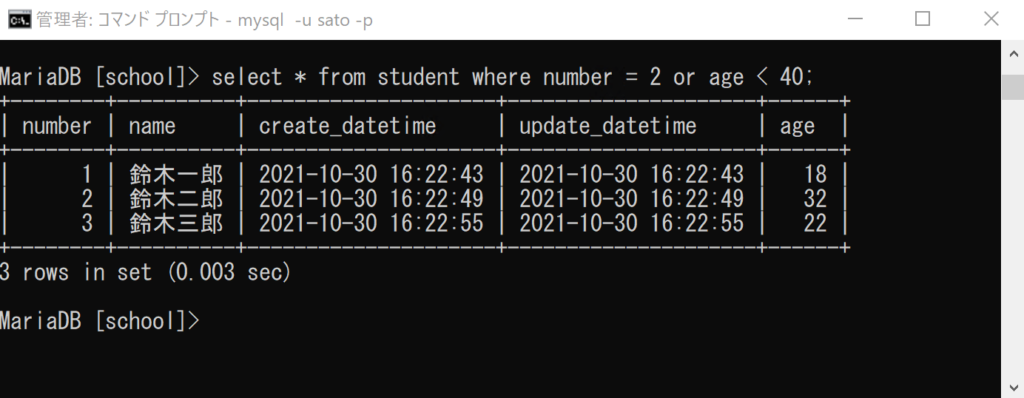
「where」は「~の場合に(レコードを抽出する)」という意味でした。
ここでは「numberカラムの値が2」または「ageカラムの値が40未満」のレコードを抽出する、という意味になります。
BETWEEN
範囲指定をしてデータを抽出することができます。
コマンドプロンプトで以下のSQLを実行します。
select * from student where age between 20 and 40;
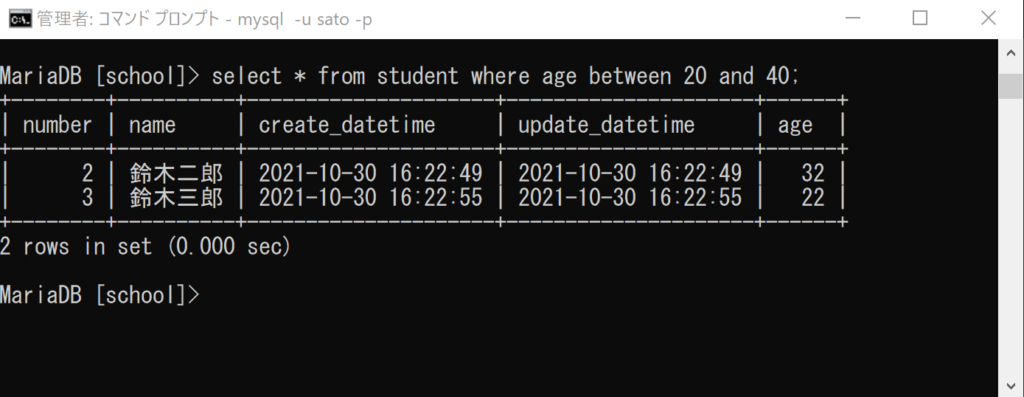
「where」は「~の場合に(レコードを抽出する)」という意味でした。
次の「age between 20 and 40」は、「カラムageについて20~40の間のデータを抽出する」という意味になります。
LIKE
指定した文字で検索してデータを抽出することができます。
コマンドプロンプトで以下のSQLを実行します。
select * from student where name like ‘%三%’;
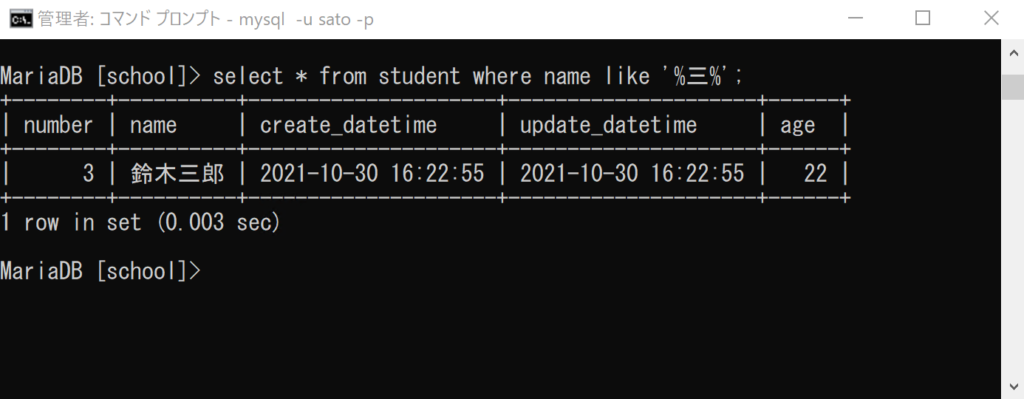
「where」は「~の場合に(レコードを抽出する)」という意味でした。
次の「name like」は、「カラムnameの値が~のようであれば」という意味です。
それに続く「’%三%’」は、部分一致で「三」という文字があるかを検索しています。「%」で囲むと部分一致を示します。
つなげると「カラムnameの値が(部分一致で)’三’を含む場合に、そのレコードを抽出する」という意味になります。
LIMIT
LIMITを指定すると、取得するレコード件数に制限をかけることができます。
コマンドプロンプトで以下のSQLを実行します。
select * from student limit 2;
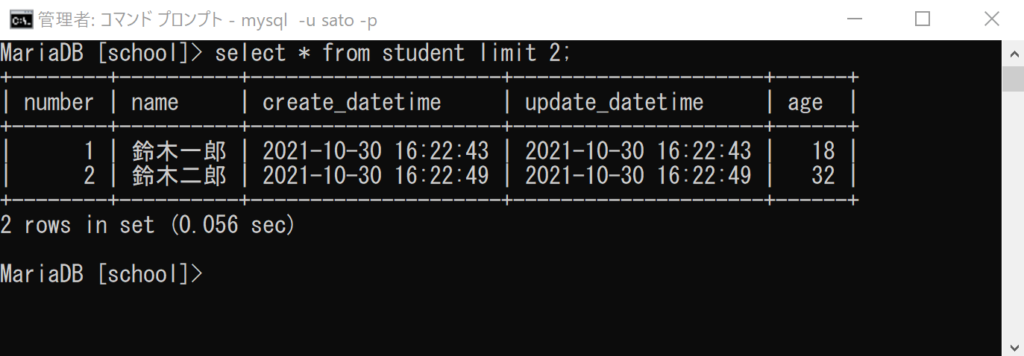
レコードは5つありますが、「limit 2」を指定することで、2件のみ抽出できていることが分かります。
OFFSET
OFFSETを指定することで、取得するレコードの開始位置を指定することができます。
コマンドプロンプトで以下のSQLを実行します。
select * from student limit 2 offset 2;
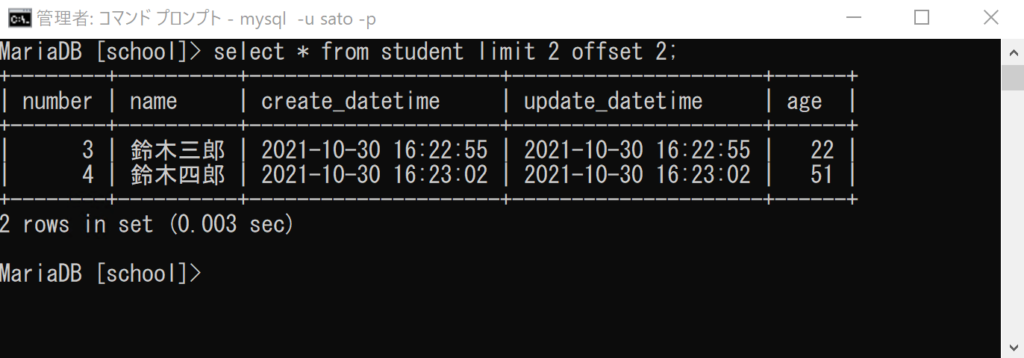
offsetを指定しないと、numberが1の鈴木一郎さんから取得できますが、「offset 2」を付けることで開始位置を2つ後ろにずらし、numberが3の鈴木三郎さんから取得できていることが分かります。あわせて「limit 2」を指定しているので、2つのデータのみを取得しています。

本節の説明は以上になります。
